
作者 | ZeR0
編輯 | 漠影
芯東西3月24日報道,當今全世界身價最高的兩位華人,一位賣鏟,一位賣水。
第一名是輝達創始人兼CEO黃仁勛,靠給AI淘金者們賣GPU,把輝達推上全球市值第三的寶座;另一位是農夫山泉創始人、董事長兼總經理鐘睒睒,憑「大自然的搬運工」笑傲飲用水江湖。
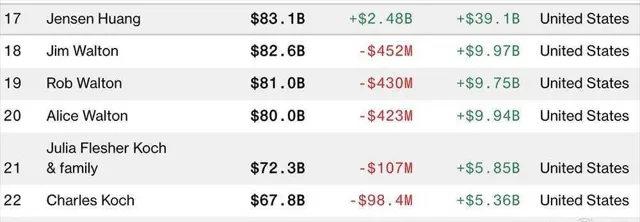
▲在最新彭博億萬富豪榜中,黃仁勛是第17名 ,鐘睒睒是第23名
當前,輝達市值已經穩坐2萬億美元大關,與蘋果的市值差距縮小到0.3萬億美元。

▲全球市值TOP10中,輝達過去30天股價漲幅最大(圖源:Companies Market Cap)
在本周輝達GTC大會上,黃仁勛一本正經地說:「我們可以附帶著賣熱水。」
這可不是句玩笑話,黃仁勛是有數據依據的:輝達DGX新機的液冷散熱,液體入口溫度是25℃,接近室溫;出口溫度升高到45℃,接近按摩浴缸的水溫,流速是2L/s。
當然了,比起賣水,GPU算力才是輝達手裏的印鈔機。
人稱「皮衣刀客」的黃仁勛,一貫具有極強的危機感和風險意識,永遠在提前為未來鋪路。再加上芯片行業是一個高風險高成本低容錯的行業,一步走錯,可能就會跌落神壇,滿盤皆輸。所以在AI算力需求空前爆發、一眾強敵虎視眈眈的關鍵時刻,輝達不敢在新品上有絲毫懈怠,必然會在短期內打出最大爆發,讓對手們望塵莫及。
當競爭對手們還在以追趕輝達旗艦GPU為目標時,黃仁勛已經站在next Level,捕捉到數據中心客戶需求的痛點——單芯不頂事,真正頂事的是解決系統級效能和能效提升的挑戰。

拿單個旗艦GPU比,輝達的芯片確實配得上「核彈」稱號,效能猛,功耗也高。但黃仁勛厲害在早就跳出芯片本身,不斷向數據中心客戶灌輸「買得越多 省得越多」的理念,簡而言之買輝達的AI系統方案比其他方案更快更省錢。
從Blackwell架構設計到AI基礎設施的技術布局,都能反映黃仁勛對未來市場需求和行業趨勢的前瞻性判斷:
1、莫耳定律帶動效能提升越來越捉襟見肘,單die面積和晶體管快到極限,後續芯片叠代必須包括高頻寬記憶體、Chiplet先進封裝、片內互聯等技術的創新組合。再加上片外互連等高效能通訊的最佳化,共同構成了輝達打造出專為萬億參數級生成式AI設計的系統的基礎。
2、未來,數據中心將被視為AI工廠,在整個生命周期裏,AI工廠的目標是產生收益。不同於消費級市場單賣顯卡,數據中心市場是個系統級生意,單芯片峰值效能參考價值不大,把很多GPU組合成一個「巨型GPU」,使其在完成同等計算任務時耗費更少的卡、時間和電力,對客戶才能帶來更大的吸重力。
3、AI模型的規模和數據量將持續增長:未來會用多模態數據來訓練更大的模型;世界模型將大行其道,學習掌握現實世界的物理規律和常識;借助合成數據生成技術,AI甚至能模仿人類的學習方式,聯想、思考、彼此相互訓練。輝達的目標是不斷降低與計算相關的成本和能耗。
4、高效能推理或生成將至關重要。雲端執行的輝達GPU可能有一半時間都被用於token生成,執行大量的生成式AI任務。這既需要提高吞吐量,以降低服務成本,又要提高互動速度以提高使用者體驗,一個GPU難以勝任,因此必須找到一種能在許多GPU上並列處理模型工作的方法。
一、最強AI芯片規格詳解:最大功耗2700W,CUDA配置成謎
本周二,輝達釋出新一代Blackwell GPU架構,不僅刻意弱化了單芯片的存在感,而且沒有明確GPU的代號,而是隱晦地稱作「Blackwell GPU」。這使得被公認遙遙領先的Blackwell架構多少籠上了一抹神秘色彩。
在GTC大會現場,輝達副總裁Ian Buck和高級副總裁Jonah Alben向智東西&芯東西等全球媒體進一步分享了關於Blackwell架構設計的背後思考。結合22頁輝達Blackwell架構技術簡報,關於GB200超級芯片、HGX B200/B100、DGX超級電腦等的配置細節被進一步披露。
根據現有資訊,全新Blackwell GPU沒有采用最先進的3nm制程工藝,而是繼續沿用4nm的客製增強版工藝台積電4NP,已知的芯片款式有3類——B100、B200、GB200超級芯片。
B100不是新釋出的主角,僅在HGX B100板卡中被提及。B200是重頭戲,GB200又進一步把B200和1顆72核Grace CPU拼在一起。
B200有2080億顆晶體管,超過p00(800億顆晶體管)數量的兩倍。輝達沒透露單個Blackwell GPU die的具體大小,只說是在reticle大小尺寸限制內。上一代單die面積為814mm²。由於不知道具體數位,不好計算B200在單位面積效能上的改進振幅。
輝達透過NV-HBI高頻寬介面,以10TB/s雙向頻寬將兩個GPU die互聯封裝,讓B200能像單芯片一樣執行,不會因為通訊損耗而損失效能,沒有記憶體局部性問題,也沒有緩存問題,能支持更高的L2緩存頻寬。但輝達並沒有透露它具體采用了怎樣的芯片封裝策略。
前代Gp00超級芯片是把1個p00和1個Grace CPU組合。而GB200超級芯片將2個Blackwell GPU和CPU組合,每個GPU的滿配TDP達到1200W,使得整個超級芯片的TDP達到2700W(1200W x 2+300W)。
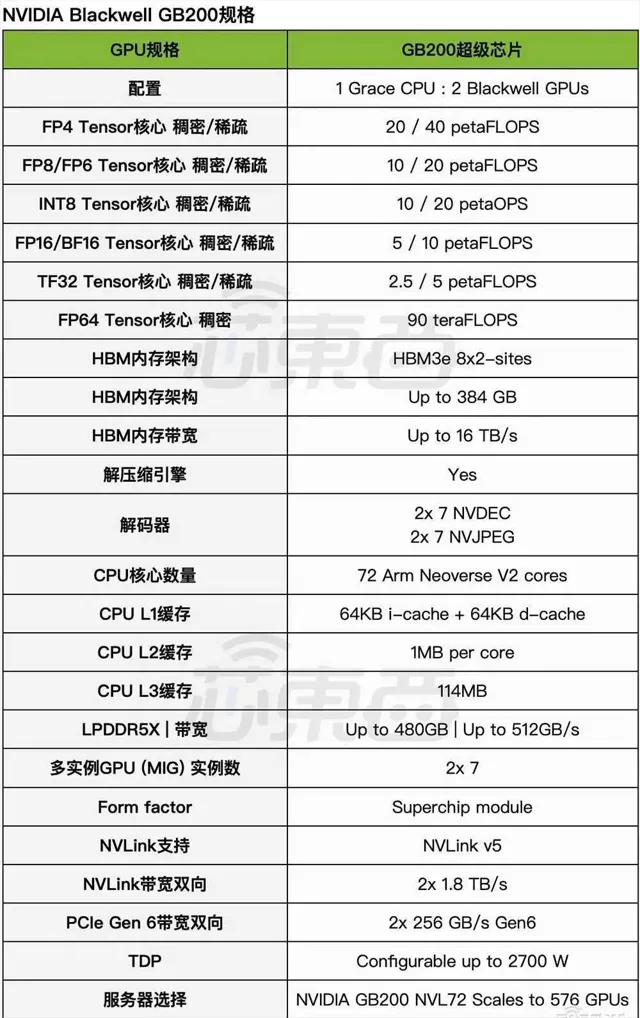
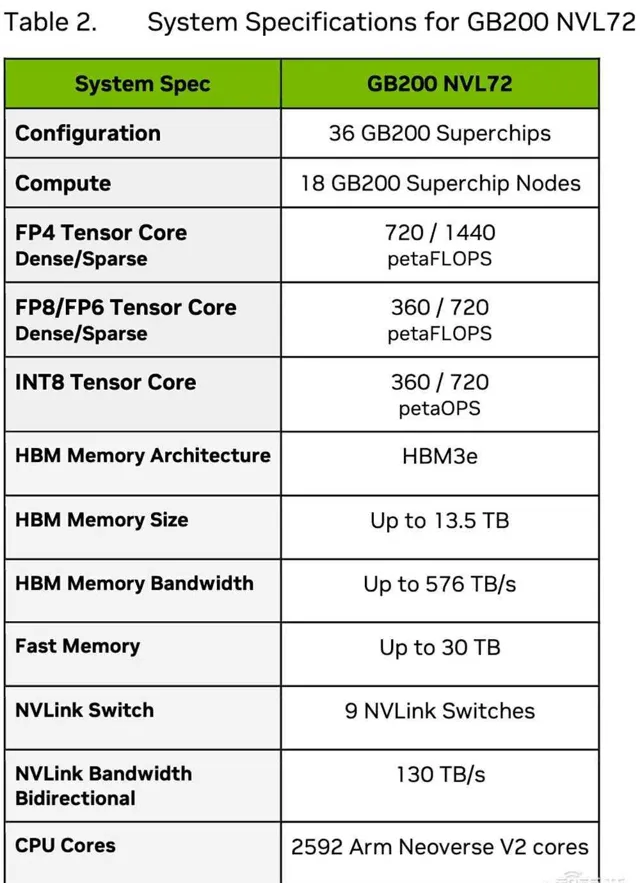
▲Blackwell GB200規格(圖源:芯東西根據技術簡報表格譯成中文)
值得關註的是,Blackwell架構技術簡報僅披露了Tensor核心數據,對CUDA核心數、Tensor核心數、向量算力等資訊只字未提。除了FP64是稠密,其他數據格式都顯示了稀疏算力。
相比之下,標準FP64 Tensor核心計算效能提升振幅不大,p00和p00是67TFLOPS,GB200超級芯片是90TFLOPS,比上一代提高34%。
一種可能的推測是Blackwell架構的設計全面偏向AI計算,對高效能計算的提升不明顯。如果晶體管都用於堆Tensor核心,它的通用能力會變弱,更像個偏科的AI NPU。
由於采用相同的基礎設施設計,從Hopper換用Blackwell主機板就像推拉抽屜一樣方便。
技術簡報披露了Blackwell x86平台HGX B100、HGX B200的系統設定。HGX B200搭載8個B200,每個GPU的TDP為1000W;HGX B100搭載8個B100,每個GPU的TDP為700W。
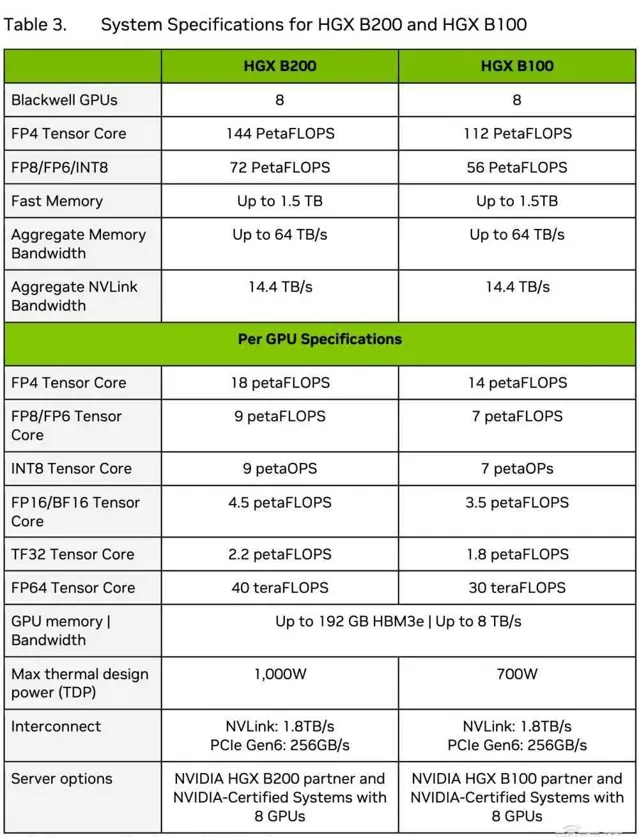
▲HGX B200和HGX B100系統規格(圖源:Blackwell架構技術簡報)
在數據中心Blackwell GPU釋出後,業界關註焦點移向同樣基於Blackwell架構的遊戲顯卡RTX 50系列。目前距離RTX 50系列GPU的釋出日期還很遙遠,最快也得到今年年底,慢點可能要到明年甚至是後年。
不過現在已經有很多關於配置的傳言,比如采用台積電3nm和28Gbps GDDR 7視訊記憶體、最大匯流排寬度有384bit和512bit兩種說法,芯片包括從入門級GB207到高端級GB202,會繼續最佳化路徑追蹤、光線追蹤。
二、8年AI訓練算力提升1000倍,輝達是怎麽做到的?
從2016年Pascal GPU的19TFLOPS,到今年Blackwell GPU的20PFLOPS,黃仁勛宣布輝達用8年將單卡AI訓練效能提升了1000倍。

這個聽起來令人心潮澎湃的倍數,除了得益於制程工藝叠代、更大的HBM容量和頻寬、雙die設計外,數據精度的降低起到關鍵作用。

多數訓練是在FP16精度下進行,但實際上不需要用這麽高的精度去處理所有參數。輝達一直在探索怎麽透過混合精度操作來在降低記憶體占用的同時確保吞吐量不受影響。
Blackwell GPU內建的第二代Transformer引擎,利用先進的動態範圍管理演算法和細粒度縮放技術(微型tensor縮放)來最佳化效能和精度,並首度支持FP4新格式,使得FP4 Tensor核效能、HBM模型規模和頻寬都實作翻倍。

同時TensorRT-LLM的創新包括量化到4bit精度、具有專家並列對映的客製化內核,能讓MoE模型即時推理使用耗費硬體、能量、成本。NeMo框架、Megatron-Core新型專家並列技術等都也為模型訓練效能的提升提供了支持。
降精度的難點是兼顧使用者對準確率的需求。FP4並不在什麽時候都有效,輝達專門強調的是對混合專家模型和大語言模型帶來的好處。把精度降到FP4可能會有困惑度增加的問題,輝達還貼心地加了個過渡的FP6,這個新格式雖然沒什麽效能優勢,但處理數據量比FP8減少25%,能緩解記憶體壓力。
三、90天2000塊GPU訓練1.8萬億參數模型,打破通訊瓶頸是關鍵
和消費級顯卡策略不同,面向數據中心,黃仁勛並不打算透過賣一顆兩顆顯卡來賺取蠅頭小利,而是走「堆料」路線來幫客戶省錢。
無論是大幅提高效能,還是節省機架空間、降低電力成本,都對在AI大模型競賽中爭分奪秒的企業們相當有吸重力。
黃仁勛舉的例子是訓練1.8萬億參數的GPT-MoE混合專家模型:
用25000個Ampere GPU,需要3~5個月左右;要是用Hopper,需要約8000個GPU、90天來訓練,耗電15MW;而用Blackwell,同樣花90天,只需2000個GPU,耗電僅4MW。
省錢與省電成正比,提高能效的關鍵是減少通訊損耗。據Ian Buck和Jonah Alben分享,在GPU集群上執行龐大的GPT-MoE模型,有60%的時間都花在通訊上。

Ian Buck解釋說,這不光是計算問題,還是I/O問題,混合專家模型帶來更多並列層和通訊層。它將模型分解成一群擅長不同任務的專家,誰擅長什麽,就將相應訓練和推理任務分配給誰。
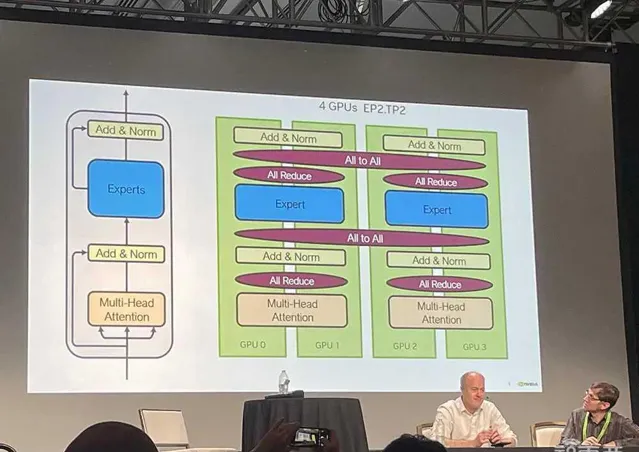
所以實作更快的NVLink Switch互連技術非常重要。所有GPU必須共享計算過程中的結果,在DGX GB200 NVL72機架中,多節點All-to-All通訊、all-Reduce的通訊速度都較過去暴漲。

全新NVLink Switch芯片總頻寬達到7.2TB/s,支持GPU縱向擴充套件,能驅動4個1.8TB/s的NVLink埠。而PCIe 9.0 x16插槽預計要到2032年才能提供2TB/s的頻寬。
從單卡來看,相比p00,Blackwell GPU的訓練效能僅提高到2.5倍,即便按新添的FP4精度算,推理效能也只提高到5倍。
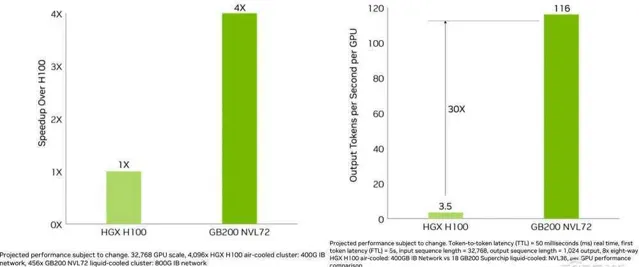
但如果從系統效能來看,相比上一代Hopper集群,Blackwell可將1.8萬億參數的GPT-MoE推理效能提高到30倍。

▲基於第二代Transformer引擎的GB200 1.8T GPT-MoE即時推理效能
藍色曲線代表p00,紫紅色曲線代表B200,從藍到紫只涉及從Hopper單芯設計到Blackwell雙芯設計的芯片升級。加上全新FP4、Tensor核心、Transformer引擎、NVLink Switch等技術,效能漲到如綠色曲線代表的GB200所示。
下圖中Y軸是每GPU每秒token數,代表數據中心吞吐量;X軸是每使用者每秒token數,代表使用者的互動體驗,越靠近右上方的數據代表兩種能力都很強。綠色曲線是峰值效能線。

為了找出GPT-MoE訓練的正確並列配置,輝達做了大量實驗(得到圖中的藍點),以探索建立硬體和切割模型的正確方法,使其盡可能實作高效執行。其探索包括一些軟體重分塊、最佳化策略判斷,並將大模型分布在不同的GPU中來滿足效能需求。
左側TP2代表2個GPU的Tensor並列,EP8代表跨8個GPU的專家並列,DP4代表跨4個GPU的數據並列。右側有TP4,跨4個GPU的Tensor並列、跨16個GPU的專家並列。軟體層面不同的配置和分布式策略會導致執行時產生不同結果。
黃仁勛還從通訊耗材的角度來說明Blackwell DGX系統能夠更省電省錢。

他解釋說在DGX背面NVLink主幹數據以130TB/s雙向頻寬透過機箱背面,比互聯網總頻寬還高,基本上1秒鐘內能將所有內容發送給每個人,裏面有5000根NVLink銅纜、總長度2英裏。
如果用光傳輸,就必須使用光模組和retimer,這倆器件要耗電20kW,僅是光模組就要耗電2kW。只是為了驅動NVLink主幹,輝達透過NVLink Switch不耗電就能做到,還能節省20kW用於計算(整個機架功耗為120kW)。
四、集結高速通訊能力,在單機架上打造E級算力AI超級電腦
更快的網路,帶來了更強大的計算效率。
DGX GB200 NVL72采用液冷機架式設計,顧名思義,透過第五代NVLink以1.8TB/s通訊速度將72個GPU互連。一個機架最多有高達130TB/s的GPU頻寬、30TB記憶體,訓練算力接近E級、推理算力超過E級。
相較相同數量p00 GPU的系統,GB200 NVL72為GPT-MoE-1.8T等大語言模型提供4倍的訓練效能。在GB200 NVL72中用32個Blackwell GPU執行GPT-MoE-1.8T,速度是64個Hopper GPU的30倍。
黃仁勛說,這是世界上第一台單機架EFLOPS級機器,整個地球也不過兩三台E級機器。
對比之下,8年前,他交給OpenAI的第一台DGX-1,訓練算力只有0.17PFLOPS。
p00搭配的第四代NVLink總頻寬是900GB/s,第五代則翻倍提升到1.8TB/s,是PCle 5頻寬的14倍以上。每個GPU的NVLink數量沒變,都是18個鏈路。CPU與B200間的通訊速度是300GB/s,比PCIe 6.0 x16插槽的256GB/s更快。

GB200 NVL72需要強大的網路來實作最佳效能,用到了輝達Quantum-X800 InfiniBand、Spectrum-X800乙太網路、BlueField-3 DPU和Magnum IO軟體。

兩年前,黃仁勛看到的GPU是HGX,重70磅,有35000個零件;現在GPU有60萬個零件,重3000磅,「應該沒有一頭大象沈」,「重量跟一輛碳纖維法拉利差不多」。
第五代NVLink把GPU的可延伸數量提高到576個。輝達還推出一些AI安全功能來確保數據中心GPU的最大正常執行時間。8個GB200 NVL72機架可組成1個SuperPOD,與800Gb/s InfiniBand或乙太網路互連,或者可以建立一個將576個GPU互連的大型共享記憶體系統。
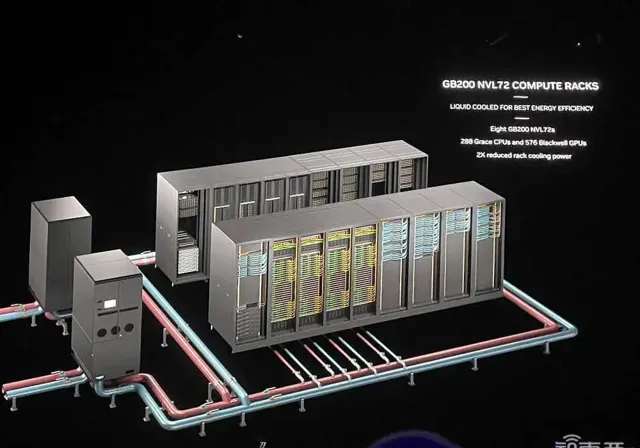
據Ian Buck透露,目前最大配置的576個GPU互連主要是用於研究,而不是生產。
結語:八年伏脈,一朝登頂
從打造垂直生態的角度來看,輝達越來越像芯片和AI計算領域的蘋果,在研發、工程和生態方面都展現出強大而全面的統治力。
就像蘋果用App Store牢牢粘住開發者和消費者一樣,輝達已經打造了完備的芯片、系統、網路、安全以及各種開發者所需的軟體,用最好的軟硬體組合不斷降低在GPU上加速AI計算的門檻,讓自己始終處於企業及開發者的首選之列。
在數據中心,看單個芯片峰值效能沒什麽意義,很多芯片連在一起實作的實質性算力改進,才有直接參考性。所以黃仁勛要賣「系統」,是一步跨到數據中心客戶算力需求的終點。
相比上一代Hopper,Blackwell GPU的主要最佳化沒有依賴制程工藝技術的提升,而是更先進的記憶體、更快的片內互聯速度,並透過升級片間互連、多機互連的速度以及可延伸性、管理軟體,消除大量數據處理導致的通訊瓶頸,從而將大量GPU連成一個更具成本效益的強大系統。
草蛇灰線,伏脈千裏。將芯片、儲存、網路、軟體等各環節協同的系統設計之路,輝達早在8年前就在探索。2016年4月,黃仁勛親手將第一台內建8個P100 GPU的超級電腦DGX-1贈予OpenAI團隊。之後隨著GPU和互連技術的更新換代,DGX也會隨之升級,系統效能與日俱增。
數據中心AI芯片是當前矽谷最熱門的硬體產品。而輝達是這個行業的規則制定者,也是離生成式AI客戶需求最近的企業,其對下一代芯片架構的設計與銷售策略具有行業風向標的作用。透過實作讓數百萬個GPU共同執行計算任務並最大限度提高能效的基礎創新,黃仁勛反復強調的「買得越多 省得越多」已經越來越具有說服力。











